
The field of image synthesis has witnessed significant advancements with the introduction of Latent Diffusion Models (LDMs). These models, grounded in the principles of diffusion processes and latent space representation, offer a novel approach to generating high-quality images. This article delves into the technical underpinnings of LDMs, their architecture, and their application in image synthesis.
Understanding Latent Diffusion Models
Latent Diffusion Models are a class of generative models that combine the strengths of diffusion processes and latent variable models. Diffusion models, which are inspired by the physical process of diffusion, involve gradually transforming a simple initial distribution into a complex data distribution. This transformation is done through a series of small, reversible steps, allowing the model to learn and generate data with intricate structures.
In the context of LDMs, the diffusion process operates within a latent space, a compressed representation of the data that captures its essential features. This approach not only reduces the computational complexity but also allows the model to focus on learning the most salient aspects of the data, leading to more efficient and effective image generation.
Architecture of Latent Diffusion Models
The architecture of Latent Diffusion Models is composed of two primary components: the encoder-decoder framework and the diffusion process.
Encoder-Decoder Framework
The encoder-decoder framework is central to LDMs. The encoder maps the input data, such as an image, into a latent space, creating a compact representation that encapsulates the key features of the data. This latent representation is then passed through the diffusion process, where noise is gradually added and then removed, simulating the diffusion process in reverse.
The decoder then reconstructs the data from the latent representation, generating a high-quality image. The use of a latent space allows the model to operate on a lower-dimensional representation of the data, making the diffusion process more computationally feasible.
Diffusion Process
The diffusion process in LDMs is modeled as a Markov chain, where each step involves adding a small amount of noise to the latent representation and then denoising it to approximate the target data distribution. This process is iterative, with each step refining the latent representation until it converges to a stable distribution that corresponds to the desired output.
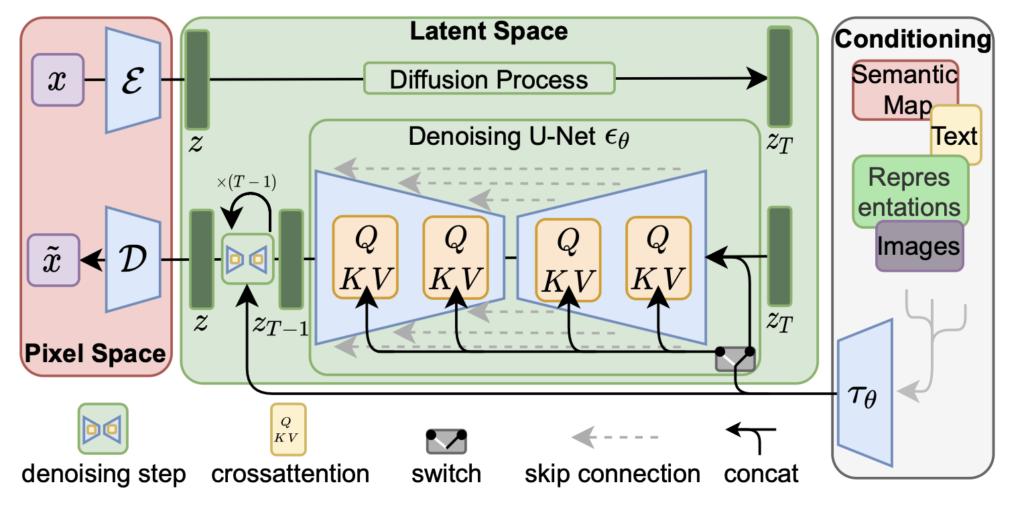
The key innovation of LDMs lies in applying the diffusion process within the latent space rather than directly on the data. This allows the model to capture complex data distributions with fewer computational resources, making it possible to generate high-resolution images with detailed structures.
Training Latent Diffusion Models
Training LDMs involves optimizing the parameters of both the encoder-decoder framework and the diffusion process. The objective is to minimize the difference between the generated images and the real data, measured using a loss function such as the Kullback-Leibler (KL) divergence or the mean squared error (MSE).
Latent Space Regularization
One of the challenges in training LDMs is ensuring that the latent space is well-structured, meaning that similar data points are mapped to nearby regions in the latent space. This is achieved through latent space regularization, a technique that imposes additional constraints on the encoder to encourage the latent representations to follow a smooth, continuous distribution.
Noise Scheduling
Another critical aspect of training LDMs is noise scheduling, which determines the amount of noise added during each step of the diffusion process. A carefully designed noise schedule is crucial for balancing the trade-off between exploration and exploitation in the latent space. Too much noise can lead to poor image quality, while too little noise can result in overfitting to the training data.
Applications of Latent Diffusion Models in Image Synthesis
Latent Diffusion Models have been successfully applied to various image synthesis tasks, including image generation, inpainting, and super-resolution.
Image Generation
In image generation, LDMs are capable of producing high-resolution images from random latent vectors. The latent space representation allows the model to capture the underlying structure of the data, enabling it to generate realistic images with fine details.
Image Inpainting
Image inpainting, or the task of filling in missing parts of an image, is another area where LDMs excel. By leveraging the latent space, LDMs can infer the missing content based on the surrounding context, producing seamless and coherent completions.
Super-Resolution
LDMs are also effective in super-resolution tasks, where the goal is to enhance the resolution of low-quality images. The diffusion process within the latent space allows the model to upsample images while preserving the fine details and textures, resulting in high-quality super-resolved images.
Paper
Conclusion
Latent Diffusion Models represent a significant advancement in the field of image synthesis, offering a powerful and efficient approach to generating high-quality images. By operating in a latent space and employing a diffusion process, LDMs are able to capture complex data distributions with fewer computational resources. As research in this area continues to evolve, LDMs are likely to play a central role in the future of image synthesis and other generative tasks.
Read related articles in our Blog: